
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- qiskit #QuantumComputer #QuantumMachine #양자컴퓨터 #양자 #키스킷
- ibm #qiskit #quantum # quantumcomputer #quantumcomputing #quantummachine #quantumengineering #quantumbit #qbit
- qiskit #
- qiskit #qiskitHackerthon
- Today
- Total
인일의 공부 블로그
Elastic search with CLIP 본문
포스팅 개요
아래 공식 블로그를 요약하고 튜토리얼을 진행했습니다.
https://www.elastic.co/kr/blog/5-technical-components-image-similarity-search
이미지 유사성 검색의 5가지 기술 구성 요소 | Elastic.co
이미지 유사성 검색을 자세히 살펴보고, 유사성 검색 애플리케이션을 구현하는 데 수반되는 5가지 구성 요소를 이해하고, 성능에 중요한 기술적 고려 사항을 숙지합니다....
www.elastic.co
https://www.elastic.co/kr/blog/how-to-deploy-nlp-text-embeddings-and-vector-search
NLP를 배포하는 방법: 텍스트 임베딩 및 벡터 검색
이 블로그에서는 감정 분석을 예제 작업으로 삼아, 자연어 처리(Natural Language Processing, NLP)를 위한 딥 러닝 모델을 사용하여 시작하고 실행하는 프로세스를 설명합니다....
www.elastic.co
목차
🎈 이미지 유사성 검색 기술
- CLIP 모델은 이미지를 벡터화 하고, Elastic의 추론 엔드 포인트를 사용 할 수 있음
- 벡터 유사성 검색에서 kNN(k-nearlest neighbor?) - 자원 많이 듦 → ANN(Aporociate nearlest neighborhood?) 사용.
- 이미지 임베딩 모델로 CLIP 사용
대화형 어플리케이션 로드(frontend)
-> user 선택
-> app이 clip 모델 적용 & 이미지 벡터화, 임베딩 고밀도 벡터로 저장
-> app이 Elasticsearch에서 kNN 쿼리시작 & 임베딩을 가져와 ANN으로 반환
-> app 응답 처리 후 하나 이상 일치하는 이미지 렌더링

🎈 CLIP 의 이미지 벡터화 방법
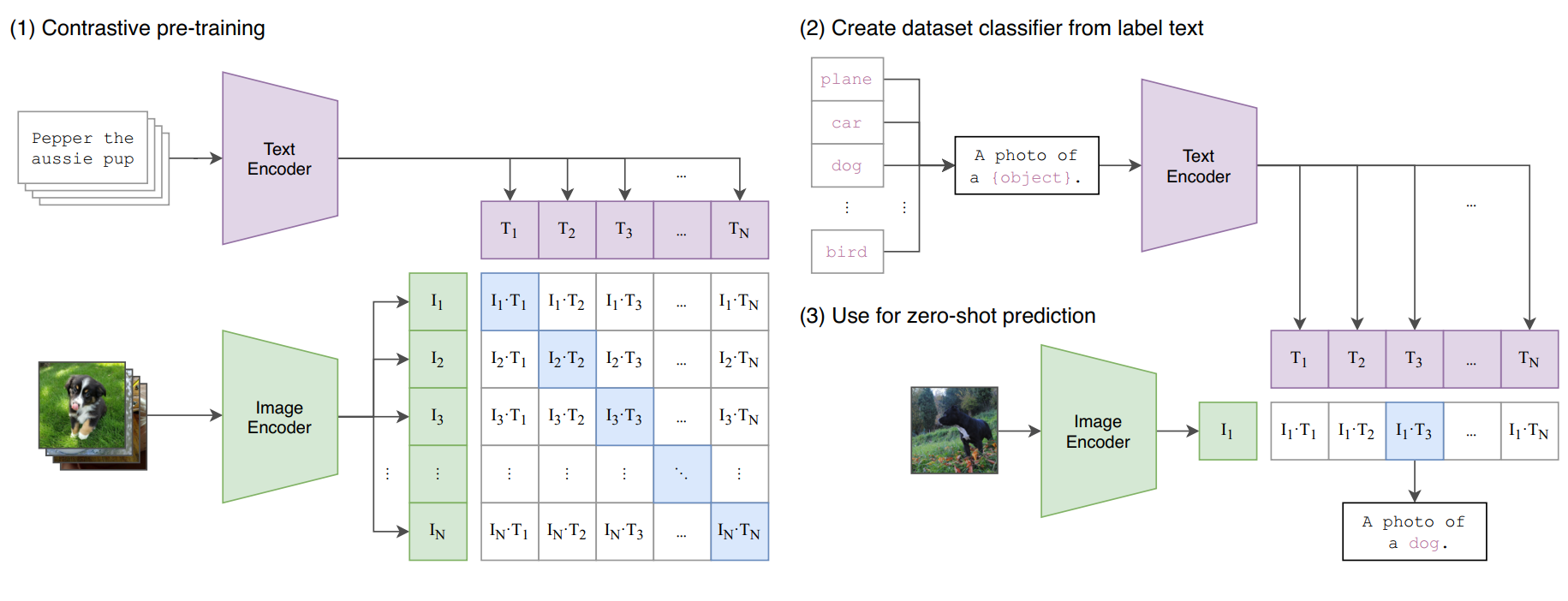
1. Constrastive pre-training
- Image와 Text를 각각 다른 인코드를 사용해 임베딩 벡터로 변환
- 이미지 벡터와 텍스트 벡터간의 코사인 유사도 계산
- Positive Pair의 유사도를 높이고, Negative Pair의 유사도를 낮추도록 학습
2. Create dataset classifier from label text
- 데이터셋 레이블에대한 텍스트 설명 작성
- 인코더에 통과시켜 임베딩 벡터로 변환
3. Use for zero-shot predition
- "Zero-Shot" : 한번도 본적 없는 문제. 즉, 한번도 학습 한 적 없는 문제에 대해 대입.
- 가장 높은 유사도를 가진 텍스트 레이블을 예측 결과로 채택
🎈 NLP에서 텍스트 임베딩, 벡터 검색
- 텍스트 임베딩 모델 배포:
- Hugging Face 모델 사용: msmarco-MiniLM-L-12-v3 Sentence Transformer를 배포하여 텍스트를 384차원 벡터로 변환.
- Elasticsearch와 Eland 활용: Docker 기반 Eland 에이전트를 사용하여 모델을 클러스터에 설치.
- 데이터 준비:
- MS MARCO 데이터 세트 사용: Microsoft Bing에서 제공하는 실제 질문-답변 데이터 활용.
- Kibana 파일 업로드: 데이터를 적절히 업로드하고, collection 인덱스 생성.
- 텍스트 임베딩 파이프라인 구성:
- Elasticsearch 수집 파이프라인 작성: 모델을 통해 텍스트 임베딩을 생성하고, 실패 시 처리 로직 정의.
- Dense Vector 필드 매핑: 384차원 임베딩을 dense_vector로 저장.
- 데이터 재색인:
- 임베딩 포함 데이터 생성: 원본 collection에서 임베딩 필드가 추가된 collection-with-embeddings로 재색인.
- 벡터 유사성 검색:
- 2단계 프로세스:
- 쿼리 텍스트 임베딩 생성: _infer API를 통해 쿼리 텍스트를 벡터로 변환.
- 벡터 기반 검색: dense_vector 필드를 기반으로 의미론적으로 유사한 문서 검색.
- 2단계 프로세스:
간단 후기
우선 어떻게 처리를 할 수 있는지 개념적으로 알아보았다. elastic 이 무엇인지, 어떻게 사용하는지도 알아봐야 실습을 진행 할 수 있을 것 같다. CLIP에 관련된 논문을 읽고 어떻게 사용되는지 의문을 느꼈는데 이와 같이 결합해서 사용 할 수 있음을 확인했다.
'AI ML DL > 머신러닝-딥러닝' 카테고리의 다른 글
| Word2Vec (1) | 2024.10.10 |
|---|---|
| [ML] 기울기 소실(Vanishing Gradient) (0) | 2022.08.23 |

