
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- qiskit #qiskitHackerthon
- qiskit #QuantumComputer #QuantumMachine #양자컴퓨터 #양자 #키스킷
- ibm #qiskit #quantum # quantumcomputer #quantumcomputing #quantummachine #quantumengineering #quantumbit #qbit
- qiskit #
- Today
- Total
인일의 공부 블로그
NLP 흐름 정리 본문
포스팅 개요
아이펠 9기 리서치 NLP 과정 딥다이브 노드 학습중 필기한 내용입니다.
목차
🎈 ELMO(Embedding from Language Models)
- ELMO는 문맥(context)을 반영한 임베딩을 pretrained model로 구현한 것
- 언어 모델을 이용하여 임베딩함
ELMO의 구조
1. character-level CNN
- 입력된 문자들 간의 관계를 파악하고 임베딩 벡터로 변환
- ELMo는 character level로 문자 인식
- 즉, character의 유니코드 ID를 입력으로 받음
i.e. 입력 단어 : '밥' -> 'ㅂ', 'ㅏ', 'ㅂ' 으로 분리 -> 각 요소에 해당하는 유니코드 {235, 176, 165}
- 단어의 시작과 끝에 스페셜 토큰 <BOW> 와 <EOW>에 해당하는 유니코드를 앞뒤로 붙임
- 만들어진 벡터에 사이즈의 필터로 convolution 하여 featuremap 제작
- max-pooling하여 최종적으로 하나의 값을 뽑아냄
2. bidirectional LSTM
- character-level CNN을 통과하여 만들어진 벡터( E1,E2,...,EN )를 전달받음
- pretrain시에 입력에 대해 다음에 올 단어를 예측함
- 'bidirectional'이기에 양방향 학습을 의미함

- pretrain 시, 순방향과 역방향으로 LSTM을 통과한 hidden vector를 내보냄
- 위 hidden vector는 softmax를 거쳐 단어를 예측
- 순방향과 역방향은 개별 모델인 것 처럼 진행하고 서로 영향을 주지 않음(cheating 일 수 있음)

3. ELMo layer
- ELMo enbedding은 pretrain이 끝나고 finetuning하는 과정에서 이루어짐
- 구하고자 하는 토큰에 대해 각 출력값을 모두 가지고 옴(character-level CNN후 벡터, LSTM layer의 hidden vector 2가지)
- 각 층마다 가중치를 곱해서 모두 더함
- 마지막 다운스트림 태스크의 가중치를 곱하여 임베딩
* 각 층에 곱해지는 가중치와 다운스트림 태스크의 가중치는 finetuning시 학습되는 값을 지칭
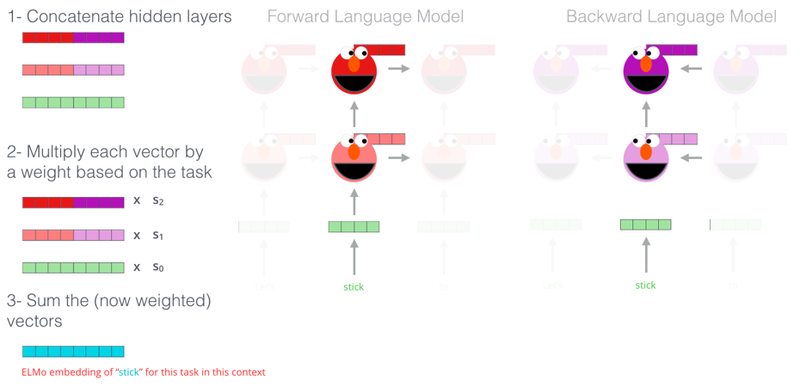
- 도메인별 어떻게 fine tuningㅇ ㅣ다른가에 대한 고민
Once pretrained, the biLM can compute representations for any task. In some cases, fine tuning the biLM on domain specific data leads to significant drops in perplexity and an increase in downstream task performance. This can be seen as a type of domain transfer for the biLM. As a result, in most cases we used a fine-tuned biLM in the downstream task. See supplemental material for details.
🎈 GPT(Generative Pre-Training Transformer)
- 트랜스포머의 decoder 구조만 이용하여 만든 네트워크
- decoder를 아주 깊고 많이 쌓아 데이터를 많이 학습시켜 성능을 높임
GPT의 구조
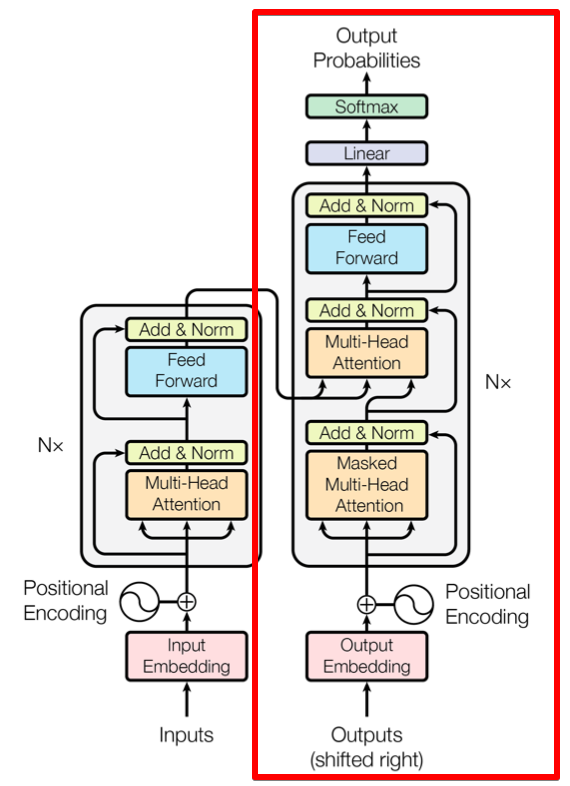
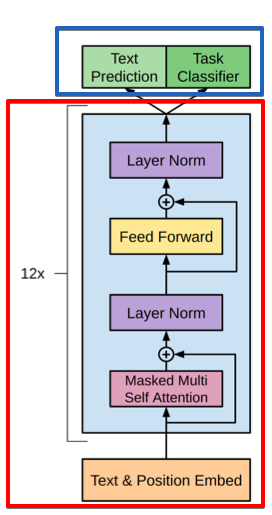
- gpt 에서 빨간 박스가 pretrain 하는 부분으로 unsupervised learning을 진행 함
1. Embedding
- BPE(Byte-pair encoding) 사용
- 모든 단어를 문자(바이트)의 집합으로 취급. 자주 등장하는 문자 쌍을 합치는 subword tokenization
- OOV 문제 해결 가능
- position encoding도 함께 사용
2. Masked Multi-Head Attention
- 모든 것을 병렬으로 처리하는 트랜스포머에게 Autoregressive 특성을 부여하기 위해 만든 장치
- 훈련 단계에서 디코더에게 정답 문장을 매 스탭 단위로 단어 하났기 알려주고 그 다음 단어를 예측하게 하는 형태로 학습
- seq2seq 모델에서 디코더가 번역 문장을 생성할때 time-step을 하나씩 거치는것과 유사
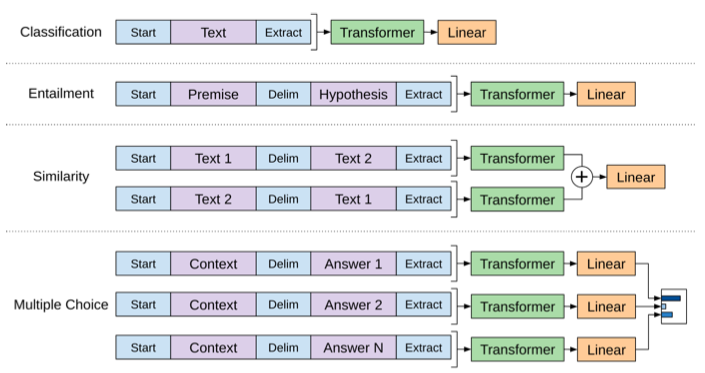
- input을 변형시켜 task를 전환 할 수 있음
i.e. classification을 풀기 위해 finetuning을 하면, <start> <input text> <extract> <class>으로 구성된 데이터셋 학습
<class>를 생성하게끔 하면 됨
🎈 BERT(Bidirectional Encoder Representations from Transformers)
- GPT는 input을 한방향으로만(uni-direction)을 보이는 반면, bert 는 양방향(bi-direction)으로 input을 확인함
- BERT는 트랜스포모머의 encoder만 사용한 모델
- ELMo와 비교하면, ELMo는 bi-LSTM을 사용했지만 독입적인 모델 처럼 학습하고 마지막 layer에서 합쳐줌. 반면, BERT는 모든 layer들이 양방향임
BERT의 구조
1. Transformer Encoding Block
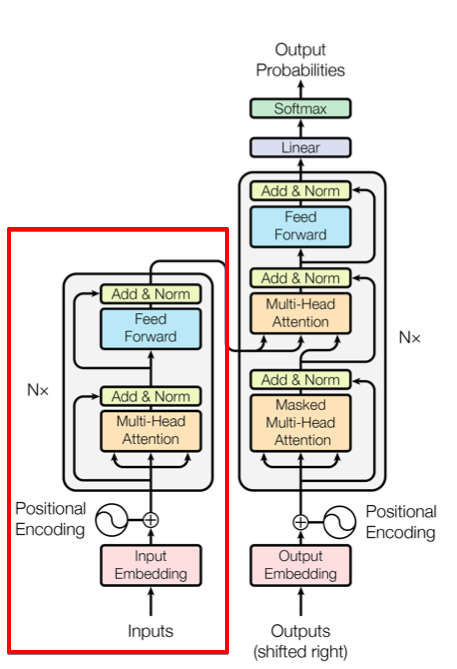
1) Embedding
- token embedding : wordpiece를 사용하여 3만개의 voca 학습. 학습한 wordpiece model을 이용하여 token 임베딩
- Segment Embedding : 두가지 sentence를 입력받기 때문에 [sep] 토큰으로 덩어리를 나눔
- position embedding : 문장 내에서 절대적인 순서를 알려줌
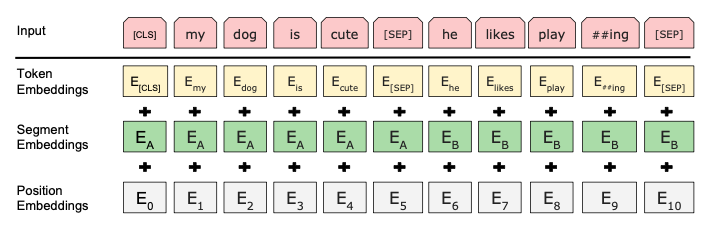
2. Activation Function : GELU
- ReLu는 음수 값의 경우 0이 되기 대문에 GELU 사용.
BERT의 학습
1. Masked LM(MLM)
- 마스크 된 토큰 만 맞추면 되는 방법. input sequence의 순서에 상관없이 전체 문장을 모두 볼 수 있음.
- MLM을 위해 BERT의 학습데이터의 전체에서 15%를 MASK 토큰으로 랜덤하게 바꿈. (이 중 80%는 MASK, 10%는 무작위 랜덤 토큰, 나머지 10%는 원래 토큰)
- pretrain을 끝낸 모델을 finetuning하면, input에 MASK 토큰이 등장하지 않기 때문에, 이것이 없는 문장도 포함되어야 함.
2. Next Sentence Prediction(NSP)
- 마스크된 토큰을 맞추는 동시에 또 다른 task를 함께 학습함
- sentence가 연속해서 오는지 여부를 학습함
[CLS]여름의 마지막 해수욕 누가 제일 늦게 바다에서 나왔나 [SEP] 그 사람이 바다의 뚜껑 닫지 않고 돌아가[SEP] → TRUE(IsNext)
[CLS]여름의 마지막 해수욕 누가 제일 늦게 바다에서 나왔나 [SEP] 한강에서 자전거 타며 아이스 아메리카노를 마시고 싶다[SEP] → FALSE(NotNext)
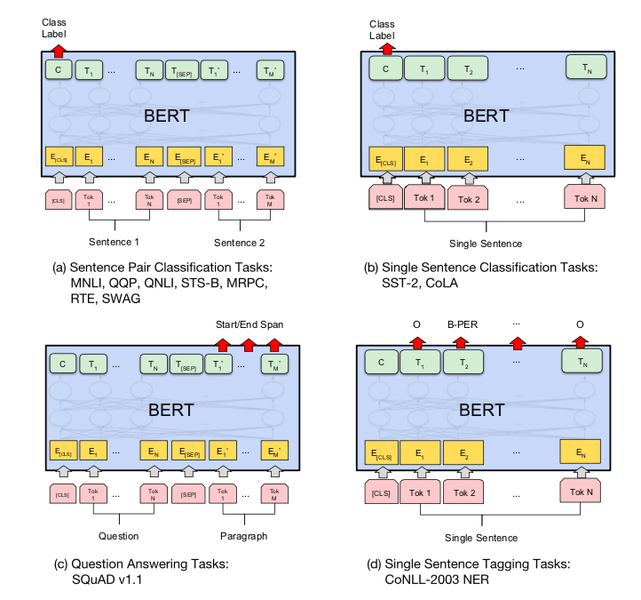
Fine-tuning Task
- classification의 경우 [CLS]토큰을, QA와 같이 문장이나 단어들이 나와야 하는 경우에는 토큰들의 벡터를 ouput layer에 넣어 ouput 산출
🎈 다른 모델들
XLNet
- 트랜스포머보다 더 넓은 범위의 문맥을 볼 수 있어 'eXtra-Long'
- GP의 AR(AutoRegressive)언어 모델과 BERT의 AE(AutoEncoding)언어 모델과 다른 퍼뮤테이션(Permutation)언어를 통해 정교한 언어모델 성능을 보이고 있음.
- 아래와 같은 AR, AE model의 단점을 극복하기 위해 퍼뮤테이션 모델 사용
- 양방향 context를 모두 볼 수 있으며, 예측해야 할 토큰 간의 dependency를 놓치지 않고 학습 가능
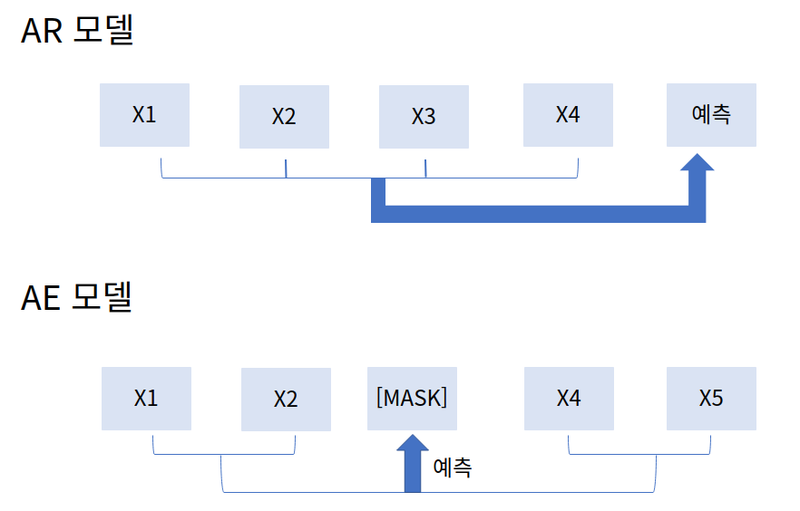
AR, AE model 극복
- AR(AutoRegressive) 모델 : 이전 문맥을 바탕으로 다음 단어 예측 (모든 문맥을 양방향으로 볼 수 없는 단점)
- AE(AutoEncoding) 모델 : 앞뒤 문맥을 모두 살펴 [MASK] 단어를 예측 (마스킹 처리된 토큰이 독립적으로 예측되므로 토큰 사이의 의존관계를 학습 할 수 없음. fine-tuning과 evaluation시 [MASK] 토큰이 보이지 않아 불일치 발생)
T5(Text-to-Text Transfer Transformer)
- BERT와 차이점은 causal decoder를 bidirectional architecture에 추가, pre-training tasks를 fill-in-the-blank cloze task로 대체
C4
- Colossal Clean Crawled Corpus(C4)라 불리는 open source pre training dataset이 있음
- T5와 C4를 가지고 fine-tuning하면 다양한 downstream task에 적용 가능
Shared Text-To-Text Framework
- T5에서는 모든 NLP task를 입력과 출력이 모두 text string인 text-to-text format으로 재구성함
- text를 입력으로 하여 모델에 넣으면 text로 결과가 나옴

- task-specific(text) prefix를 입력 시퀀스 앞에 추가해 모델에 넣은것 ( 입력 ':' 앞으로 구분되는, 자료에 대한 정보)
예1 영-독 번역
입력 - “translate English to German: That is good.”
출력 - “Das ist gut.”
예2 MNLI benchmark
입력 - “mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.”
출력 - “entailment”
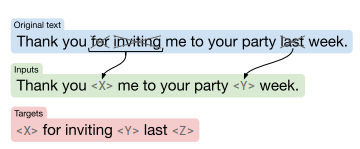
Modified MLM
- denoising objectives : T5 입력에 corrupted token을 넣어 더 좋은 성능을 낼 수 있게 함.
- T5는 타겟을 랜덤으로 샘플링하고, 입력 시퀀스의 15%의 토큰을 single sentinel token(<X>, <Y>) 로 대체
- 각 sentinel token은 어떤 word piece에도 대응하지 않는 특별한 토큰으로, 시퀀스에 유일한 토큰 ID로 지정되어 voca에 추가
- 연속된 단어는 하나의 sentinel token으로 여겨짐
- 타겟 토큰은 입력에서 사용된 sentinel token과 final sentinel token(<Z>)
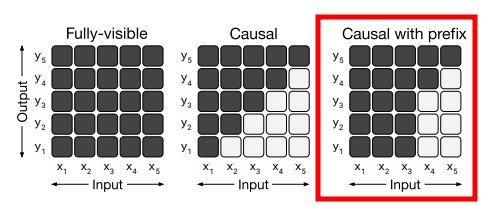
모델 아키텍처
- 어텐션 매커니즘에 의해 사용되는 mask가 다름
- 마스킹을 입력 시퀀스의 일부에 사용하는 casual masking with prefix 사용
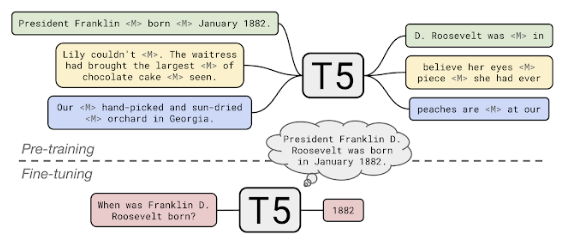
새로운 task
- closed book question answering에 대해서도 답할 수 있음
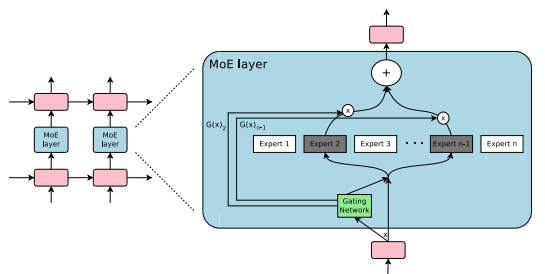
MoE(Mixture of Expert)
- Switch Transformer의 특징. FFN 레이어를 MoE레이어로 바꿈
- 하나의 모델이 다양한 개념에 대해 학습 할 수 있도록 함.
간단 후기
학습 내용이 넘 ㅜ많고 힘둘다!!!!!!!!
'AI ML DL > NLP' 카테고리의 다른 글
| 데이터 조작 방법 (0) | 2024.10.24 |
|---|---|
| Searching Algorithm (1) | 2024.10.24 |
| 텍스트 데이터 다루기 (0) | 2024.10.10 |


