
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- ibm #qiskit #quantum # quantumcomputer #quantumcomputing #quantummachine #quantumengineering #quantumbit #qbit
- qiskit #QuantumComputer #QuantumMachine #양자컴퓨터 #양자 #키스킷
- qiskit #
- qiskit #qiskitHackerthon
- Today
- Total
인일의 공부 블로그
Searching Algorithm 본문
포스팅 개요
아이펠 리서치 9기 NLP 과정 딥다이브 학습 중 작성된 내용입니다.
목차
번역의 흐름
규칙 기반 기계 번역
- 규칙 기반 기계 번역(Rule Based Machine Translation, RBMT) : 번역할 때 경우의 수를 직접 정의
- 단점 : 너무 복잡하고 오랜 시간이 필요
통계적 기계 번역
- 통계적 기계 번역(Statistical Machine Translation, SMT) : 수많은 데이터로부터 통계적 확률을 구해 번역을 진행
- 각 문장에 대한 확률을 조건부 확률을 사용해서 정의 (마크오브 결정론 사용)
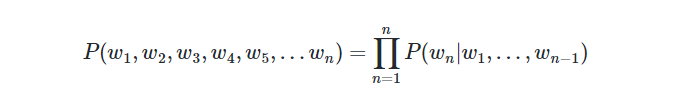
- 단점 : 희소문제가 발생함 : 충분한 데이터를 관측하지 못한 언어를 정확히 모델링 하지 못함
SMT 모델이 동작하기 위해 확률만 고려해서는 안됨. 원문과 번역문, 각 단어간의 매핑 관계를 추가로 고려해야 함
-> 정렬(Alignment)
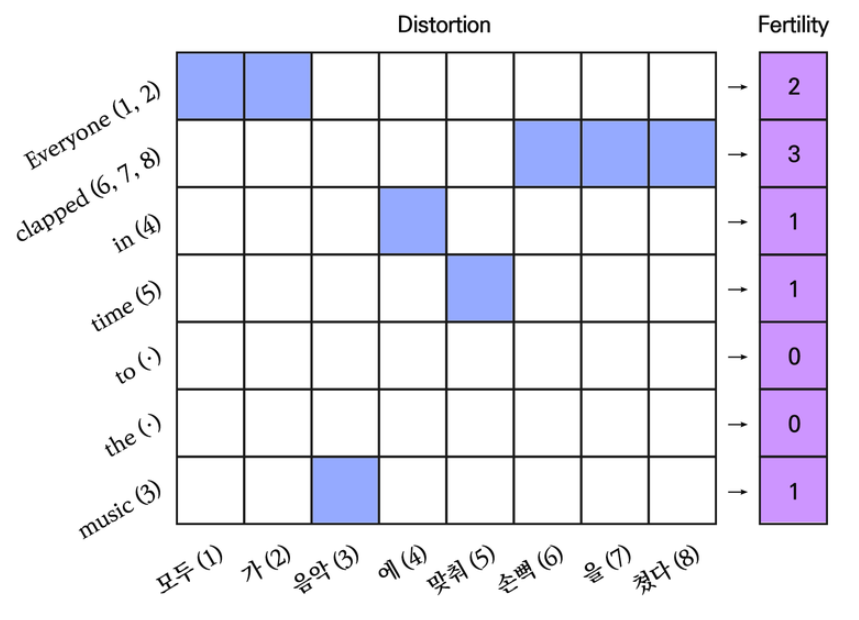
퍼틸리티(Fertility) : 원문의 각 단어가 번역 후에 몇개의 단어로 나타나는지를 의미하는 값
왜곡(Distortion) : 원문의 단어가 번역문에서 존재하는 위치를 나타냄
아래는 예문에 대한 수식이다.
E: Everyone(1, 2) clapped(6, 7, 8) in(4) time(5) to(·) the(·) music(3)
-> K: 모두(1) 가(2) 음악(3) 에(4) 맞춰(5) 손뼉(6) 을(7) 쳤다(8) p(E|K) =
{p(2|Everyone) x p(1|1, 8) x p(2|1, 8) x p(모두|Everyone) x p(가|Everyone)} x
{p(3|clapped) x p(6|2, 8) x p(7|2, 8) x p(8|2, 8) x p(손뼉|clapped) x p(을|clapped) x p(쳤다|clapped) } x
{p(1|in) x p(4|3, 8) x p(에|in)} x
{p(1|time) x p(5|4, 8) x p(맞춰|time)} x
{p(0|to) x} x
{p(0|the) x} x
{p(1|music) x p(3|7, 8) x p(음악|music)}
🎈 Greedy Decoding
- 가장 좋은 것을 먼저 취하고, 나중에 남은 것들을 넣는다.
- 간단 예시 : 1200원을 만들기!
- 동전이 500원, 400원, 100원이 있다고 가정할때, 최소 동전 갯수 사용하기
- 직관적으로는 400원을 3개 쓰는게 가장 효율적
- 그리디는 500원 2개를 먼저 배치 한 후 100원을 2개 배치할 것
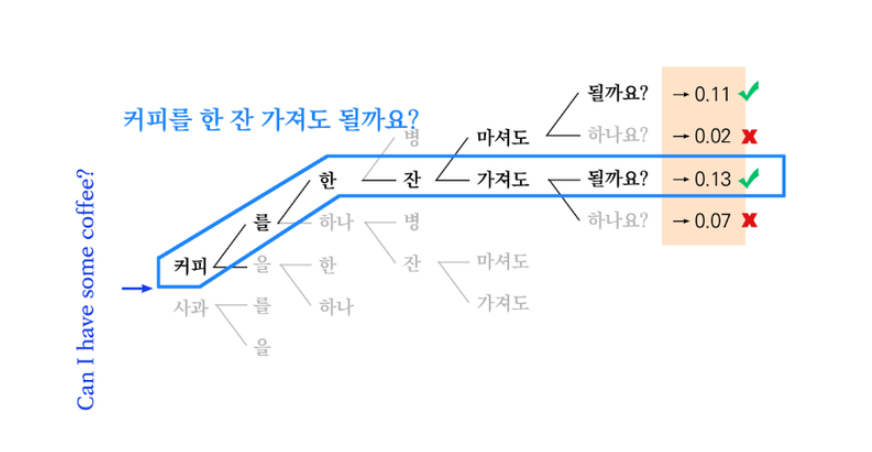
- 번역에서 Greedy decoding : 문장이 존재 할 확률을 구하고 확률이 높은 것으로 번역함.
- 아래 각 확률은 문장 안에서 단어를 포함 할 확률임. 직관적으로 '마셔도' 를선택하는게 좋아 보이나 greedy는 확률적으로 높은 (좋은 것)을 기계적으로 선택하기 때문에 '가져도'를 선택해 어색한 문장이 됨.

🎈 Beam Search
- 단어 사전으로 만들 수 있는 모든 문장을 만드는 대신, 지금 상황에서 가장 높은 확률을 갖는 Top-k 문장만 남김
- 상위 몇 개의 문장을 기억할지 Beam Size(Beam Width)로 정의 할 수 있음
- 자원이 무한하면 Beam Size를 키울수록 성능이 좋아짐
아래 단어에 대해 beam size 테스트
vocab = {
0: "<pad>",
1: "까요?",
2: "커피",
3: "마셔",
4: "가져",
5: "될",
6: "를",
7: "한",
8: "잔",
9: "도",
}
size = 2

size = 3

size = 4

사람이 직접 좋은 번역을 고를 수 있드록 상위 K개의 결괄르 보여줌
-> 모델 입장에서 뭐가 좋은 번역인지 알 수 없기에 모델 학습 단계에서는 Beam Search를 사용하지 않음
🎈 Sampling
- 확률적으로 단어를 뽑는 방법에 대해 다룸
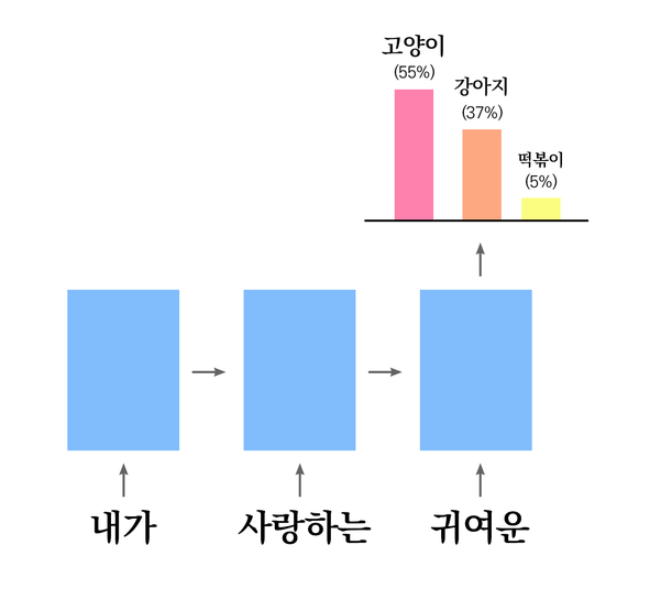
- sampling은 실제 서비스에서 거의 사용되지 않음
- 역번역 및 입실론 그레디에서 사용
간단 후기
Greedy Search라는 개념을 좋아했다는걸 다시 알게 되었다. 알고리즘 공부가 너무 재밌다!
'AI ML DL > NLP' 카테고리의 다른 글
| NLP 흐름 정리 (4) | 2024.10.28 |
|---|---|
| 데이터 조작 방법 (0) | 2024.10.24 |
| 텍스트 데이터 다루기 (0) | 2024.10.10 |


